Proteína
Definición

Las proteínas son biomoléculas grandes, o macromoléculas, que consisten en una o más cadenas largas de residuos de aminoácidos. Las proteínas realizan una amplia gama de funciones dentro de los organismos, que incluyen catalizar reacciones metabólicas, replicación del ADN, responder a estímulos y transportar moléculas de un lugar a otro. Las proteínas difieren entre sí principalmente en su secuencia de aminoácidos, que está dictada por la secuencia de nucleótidos de sus genes, y que generalmente da como resultado el plegamiento de proteínas en una estructura tridimensional específica que determina su actividad.
Una cadena lineal de residuos de aminoácidos se denomina polipéptido. Una proteína contiene al menos un polipéptido largo. Los polipéptidos cortos, que contienen menos de 20-30 residuos, rara vez se consideran proteínas y comúnmente se denominan péptidos, o a veces oligopéptidos. Los residuos de aminoácidos individuales están unidos entre sí mediante enlaces peptídicos y residuos de aminoácidos adyacentes. La secuencia de residuos de aminoácidos en una proteína está definida por la secuencia de un gen, que está codificada en el código genético. En general, el código genético especifica 20 aminoácidos estándar; sin embargo, en ciertos organismos, el código genético puede incluir selenocisteína y, en ciertas arqueas, pirrolisina. Poco después o incluso durante la síntesis, los residuos en una proteína a menudo se modifican químicamente por modificación postraduccional, que altera las propiedades físicas y químicas, Plegamiento, estabilidad, actividad y, en última instancia, la función de las proteínas. A veces, las proteínas tienen grupos no peptídicos unidos, que pueden denominarse grupos o cofactores protésicos. Las proteínas también pueden funcionar juntas para lograr una función particular, y a menudo se asocian para formar complejos proteicos estables.
Una vez formadas, las proteínas solo existen durante un cierto período y luego son degradadas y recicladas por la maquinaria de la célula a través del proceso de renovación de proteínas. La vida útil de una proteína se mide en términos de su vida media y cubre un amplio rango. Pueden existir por minutos o años con una vida promedio de 1-2 días en células de mamíferos. Las proteínas anormales o mal plegadas se degradan más rápidamente, ya sea debido a que están siendo destruidas o debido a su inestabilidad.
Al igual que otras macromoléculas biológicas como los polisacáridos y los ácidos nucleicos, las proteínas son partes esenciales de los organismos y participan prácticamente en todos los procesos dentro de las células. Muchas proteínas son enzimas que catalizan reacciones bioquímicas y son vitales para el metabolismo. Las proteínas también tienen funciones estructurales o mecánicas, como la actina y la miosina en el músculo y las proteínas en el citoesqueleto, que forman un sistema de andamiaje que mantiene la forma de la célula. Otras proteínas son importantes en la señalización celular, la respuesta inmune, la adhesión celular y el ciclo celular. En los animales, las proteínas son necesarias en la dieta para proporcionar los aminoácidos esenciales que no pueden ser sintetizados. La digestión rompe las proteínas para su uso en el metabolismo.
Las proteínas se pueden purificar a partir de otros componentes celulares usando una variedad de técnicas tales como ultracentrifugación, precipitación, electroforesis y cromatografía; el advenimiento de la ingeniería genética ha posibilitado una serie de métodos para facilitar la purificación. Los métodos comúnmente utilizados para estudiar la estructura y la función de las proteínas incluyen la inmunohistoquímica, la mutagénesis dirigida al sitio, la cristalografía de rayos X, la resonancia magnética nuclear y la espectrometría de masas.
Bioquímica

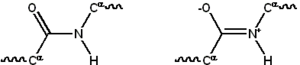
La mayoría de las proteínas consisten en polímeros lineales construidos a partir de series de hasta 20 Ldiferentes
-α-aminoácidos. Todos los aminoácidos proteinógenos poseen características estructurales comunes, que incluyen un carbono α al que están unidos un grupo amino, un grupo carboxilo y una cadena lateral variable. Solo la prolina difiere de esta estructura básica ya que contiene un anillo inusual para el grupo amino N-terminal, que fuerza a la fracción amida CO-NH a una conformación fija. Las cadenas laterales de los aminoácidos estándar, detalladas en la lista de aminoácidos estándar, tienen una gran variedad de estructuras y propiedades químicas; es el efecto combinado de todas las cadenas laterales de aminoácidos en una proteína que finalmente determina su estructura tridimensional y su reactividad química. Los aminoácidos en una cadena polipeptídica están unidos por enlaces peptídicos. Una vez vinculado en la cadena de la proteína, un aminoácido individual se llama residuo, y las series enlazadas de átomos de carbono, nitrógeno y oxígeno se conocen como cadena principal o cadena principal proteica.
-α-aminoácidos. Todos los aminoácidos proteinógenos poseen características estructurales comunes, que incluyen un carbono α al que están unidos un grupo amino, un grupo carboxilo y una cadena lateral variable. Solo la prolina difiere de esta estructura básica ya que contiene un anillo inusual para el grupo amino N-terminal, que fuerza a la fracción amida CO-NH a una conformación fija. Las cadenas laterales de los aminoácidos estándar, detalladas en la lista de aminoácidos estándar, tienen una gran variedad de estructuras y propiedades químicas; es el efecto combinado de todas las cadenas laterales de aminoácidos en una proteína que finalmente determina su estructura tridimensional y su reactividad química. Los aminoácidos en una cadena polipeptídica están unidos por enlaces peptídicos. Una vez vinculado en la cadena de la proteína, un aminoácido individual se llama residuo, y las series enlazadas de átomos de carbono, nitrógeno y oxígeno se conocen como cadena principal o cadena principal proteica.
El enlace peptídico tiene dos formas de resonancia que contribuyen a un cierto carácter de doble enlace e inhiben la rotación alrededor de su eje, de modo que los carbonos alfa son aproximadamente coplanares. Los otros dos ángulos diedros en el enlace peptídico determinan la forma local asumida por la cadena principal de la proteína. El extremo con un grupo amino libre se conoce como el término N o término amino, mientras que el final de la proteína con un grupo carboxilo libre se conoce como el término C o extremo carboxilo (la secuencia de la proteína se escribe de N- término a C-terminal, de izquierda a derecha).
Las palabras proteína , polipéptido y péptido son un tanto ambiguas y pueden superponerse en significado. La proteína se usa generalmente para referirse a la molécula biológica completa en una conformación estable, mientras que el péptido generalmente se reserva para un oligómero de aminoácido corto que a menudo carece de una estructura tridimensional estable. Sin embargo, el límite entre los dos no está bien definido y generalmente se encuentra cerca de 20-30 residuos. El polipéptido puede referirse a cualquier cadena lineal simple de aminoácidos, generalmente independientemente de la longitud, pero a menudo implica una ausencia de una conformación definida.
Interacciones
Las proteínas pueden interactuar con muchos tipos de moléculas, incluso con otras proteínas, con lípidos, con carbohidratos y con ADN.
Abundancia en las células
Se ha estimado que las bacterias de tamaño medio contienen alrededor de 2 millones de proteínas por célula (por ejemplo, E. coli y Staphylococcus aureus ). Bacterias más pequeñas, como Mycoplasma o espiroquetascontienen menos moléculas, del orden de 50,000 a 1 millón. Por el contrario, las células eucariotas son más grandes y, por lo tanto, contienen mucha más proteína. Por ejemplo, se ha estimado que las células de levadura contienen aproximadamente 50 millones de proteínas y células humanas del orden de 1 a 3 mil millones. La concentración de copias de proteínas individuales varía desde unas pocas moléculas por célula hasta 20 millones. No todos los genes que codifican proteínas se expresan en la mayoría de las células y su número depende, por ejemplo, del tipo de célula y de los estímulos externos. Por ejemplo, de las aproximadamente 20,000 proteínas codificadas por el genoma humano, solo 6,000 se detectan en células linfoblastoides. Además, la cantidad de proteínas que codifica el genoma se correlaciona bien con la complejidad del organismo. Los eucariotas, bacterias, arqueas y virus tienen en promedio 15145, 3200, 2358 y 42 proteínas codificadas respectivamente en sus genomas.
Síntesis
Biosíntesis

Las proteínas se ensamblan a partir de aminoácidos usando información codificada en genes. Cada proteína tiene su propia secuencia de aminoácidos única que se especifica mediante la secuencia de nucleótidos del gen que codifica esta proteína. El código genético es un conjunto de conjuntos de tres nucleótidos llamados codones y cada combinación de tres nucleótidos designa un aminoácido, por ejemplo, AUG (adenina-uracilo-guanina) es el código de la metionina. Debido a que el ADN contiene cuatro nucleótidos, la cantidad total de codones posibles es 64; por lo tanto, hay algo de redundancia en el código genético, con algunos aminoácidos especificados por más de un codón. Los genes codificados en el ADN se transcriben primero en ARN pre mensajero (ARNm) por proteínas como la ARN polimerasa. La mayoría de los organismos procesan el pre-ARNm (también conocido como transcripción primaria)) utilizando diversas formas de modificación postranscripcional para formar el ARNm maduro, que luego se utiliza como plantilla para la síntesis de proteínas por el ribosoma. En procariotas, el ARNm se puede usar tan pronto como se produce o puede estar unido a un ribosoma después de haberse alejado del nucleoide. Por el contrario, los eucariotes producen ARNm en el núcleo de la célula y luego lo translocan a través de la membrana nuclear hacia el citoplasma, donde entonces tiene lugar la síntesis de proteínas. La tasa de síntesis de proteínas es mayor en procariotas que en eucariotas y puede alcanzar hasta 20 aminoácidos por segundo.
El proceso de sintetizar una proteína a partir de una plantilla de ARNm se conoce como traducción. El ARNm se carga en el ribosoma y se lee tres nucleótidos a la vez, haciendo coincidir cada codón con su anticodón de emparejamiento de bases ubicado en una molécula de ARN de transferencia, que porta el aminoácido correspondiente al codón que reconoce. La enzima aminoacil tRNA sintetasa "carga" las moléculas de tRNA con los aminoácidos correctos. El polipéptido en crecimiento a menudo se denomina cadena naciente . Las proteínas siempre se biosintetizan desde el extremo N hasta el extremo C.
El tamaño de una proteína sintetizada puede medirse por el número de aminoácidos que contiene y por su masa molecular total, que normalmente se informa en unidades de dalton (sinónimo de unidades de masa atómica) o la unidad derivada kilodalton (kDa). El tamaño promedio de una proteína aumenta de Archaea a Bacteria a eucariota (283, 311, 438 residuos y 31, 34, 49 kDa respectivamente) debido a un mayor número de dominios de proteínas que constituyen proteínas en organismos superiores. Por ejemplo, las proteínas de levadura tienen un promedio de 466 aminoácidos de longitud y 53 kDa de masa. Las proteínas más grandes conocidas son los titinatos, un componente del sarcómero muscular, con una masa molecular de casi 3.000 kDa y una longitud total de casi 27.000 aminoácidos.
Síntesis química
Las proteínas cortas también pueden ser sintetizadas químicamente por una familia de métodos conocidos como síntesis de péptidos, que se basan en técnicas de síntesis orgánica tales como la ligadura química para producir péptidos con alto rendimiento. La síntesis química permite la introducción de aminoácidos no naturales en cadenas polipeptídicas, como la unión de sondas fluorescentes a cadenas laterales de aminoácidos. Estos métodos son útiles en bioquímica de laboratorio y biología celular, aunque generalmente no son para aplicaciones comerciales. La síntesis química es ineficaz para polipéptidos de más de 300 aminoácidos, y las proteínas sintetizadas pueden no asumir fácilmente su estructura terciaria nativa. La mayoría de los métodos de síntesis química proceden de C-terminal a N-terminus, frente a la reacción biológica.
Estructura

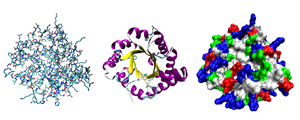
La mayoría de las proteínas se pliegan en estructuras tridimensionales únicas. La forma en que una proteína se pliega naturalmente se conoce como su conformación nativa. Aunque muchas proteínas pueden plegarse sin ayuda, simplemente a través de las propiedades químicas de sus aminoácidos, otras requieren la ayuda de chaperonas moleculares para plegarse en sus estados nativos. Los bioquímicos a menudo se refieren a cuatro aspectos distintos de la estructura de una proteína:
- Estructura primaria : la secuencia de aminoácidos. Una proteína es una poliamida.
- Estructura secundaria : estructuras locales regularmente repetidas estabilizadas por enlaces de hidrógeno. Los ejemplos más comunes son la α-hélice, la hoja β y los giros. Debido a que las estructuras secundarias son locales, muchas regiones de estructura secundaria diferente pueden estar presentes en la misma molécula de proteína.
- Estructura terciaria : la forma general de una sola molécula de proteína; la relación espacial de las estructuras secundarias entre sí. La estructura terciaria generalmente se estabiliza mediante interacciones no locales, más comúnmente la formación de un núcleo hidrofóbico, pero también a través de puentes salinos, enlaces de hidrógeno, enlaces disulfuro e incluso modificaciones postraduccionales. El término "estructura terciaria" a menudo se usa como sinónimo del término fold . La estructura terciaria es lo que controla la función básica de la proteína.
- Estructura cuaternaria : la estructura formada por varias moléculas de proteínas (cadenas de polipéptidos), generalmente llamadas subunidades de proteínas en este contexto, que funcionan como un único complejo de proteínas.
Las proteínas no son moléculas completamente rígidas. Además de estos niveles de estructura, las proteínas pueden desplazarse entre varias estructuras relacionadas mientras desempeñan sus funciones. En el contexto de estos reordenamientos funcionales, estas estructuras terciarias o cuaternarias se conocen generalmente como "conformaciones", y las transiciones entre ellas se denominan cambios conformacionales. Tales cambios a menudo son inducidos por la unión de una molécula de sustrato al sitio activo de una enzima, o la región física de la proteína que participa en la catálisis química. En solución, las proteínas también experimentan variación en la estructura a través de la vibración térmica y la colisión con otras moléculas.

Las proteínas se pueden dividir informalmente en tres clases principales, que se correlacionan con estructuras terciarias típicas: proteínas globulares, proteínas fibrosas y proteínas de membrana. Casi todas las proteínas globulares son solubles y muchas son enzimas. Las proteínas fibrosas a menudo son estructurales, como el colágeno, el componente principal del tejido conectivo o la queratina, el componente proteico del cabello y las uñas. Las proteínas de membrana a menudo sirven como receptores o proporcionan canales para que moléculas polares o cargadas pasen a través de la membrana celular.
Un caso especial de enlaces de hidrógeno intramoleculares dentro de proteínas, mal protegido del ataque de agua y, por lo tanto, promoviendo su propia deshidratación, se llaman deshidratos.
Dominios de proteínas
Muchas proteínas están compuestas por varios dominios proteicos, es decir, segmentos de una proteína que se pliegan en distintas unidades estructurales. Los dominios generalmente también tienen funciones específicas, tales como actividades enzimáticas (por ejemplo, quinasa) o sirven como módulos de unión (por ejemplo, el dominio SH3 se une a secuencias ricas en prolina en otras proteínas).
Motivo de secuencia
Las secuencias cortas de aminoácidos dentro de las proteínas a menudo actúan como sitios de reconocimiento para otras proteínas. Por ejemplo, los dominios SH3 típicamente se unen a motivos PxxP cortos (es decir, 2 prolinas [P], separadas por 2 aminoácidos no especificados [x], aunque los aminoácidos circundantes pueden determinar la especificidad de unión exacta). Se ha recopilado una gran cantidad de dichos motivos en la base de datos de motivos lineales eucariotas (ELM).
Funciones celulares
Las proteínas son los principales actores dentro de la célula, y se dice que están llevando a cabo los deberes especificados por la información codificada en los genes. Con la excepción de ciertos tipos de ARN, la mayoría de las otras moléculas biológicas son elementos relativamente inertes sobre los que actúan las proteínas. Las proteínas constituyen la mitad del peso seco de una célula de Escherichia coli , mientras que otras macromoléculas como el ADN y el ARN representan solo el 3% y el 20%, respectivamente. El conjunto de proteínas expresadas en una célula particular o tipo de célula se conoce como su proteoma.

La principal característica de las proteínas que también permite su conjunto diverso de funciones es su capacidad para unir otras moléculas específica y estrechamente. La región de la proteína responsable de unirse a otra molécula se conoce como el sitio de unión y es a menudo una depresión o "bolsillo" en la superficie molecular. Esta capacidad de unión está mediada por la estructura terciaria de la proteína, que define el bolsillo del sitio de unión, y por las propiedades químicas de las cadenas laterales de los aminoácidos circundantes. La unión a proteínas puede ser extraordinariamente estrecha y específica; por ejemplo, la proteína inhibidora de la ribonucleasa se une a la angiogenina humana con una constante de disociación subfemtomolar (<10 M) pero no se une en absoluto a su onconasa homóloga anfibia (> 1 M). Cambios químicos extremadamente menores, como la adición de un único grupo metilo a un compañero de unión a veces puede ser suficiente para casi eliminar la unión; por ejemplo, la aminoacil tRNA sintetasa específica del aminoácido valina discrimina contra la cadena lateral muy similar del aminoácido isoleucina.
Las proteínas se pueden unir a otras proteínas, así como a sustratos de moléculas pequeñas. Cuando las proteínas se unen específicamente a otras copias de la misma molécula, pueden oligomerizarse para formar fibrillas; este proceso ocurre a menudo en proteínas estructurales que consisten en monómeros globulares que se autoasocian para formar fibras rígidas. Las interacciones proteína-proteína también regulan la actividad enzimática, controlan la progresión a través del ciclo celular y permiten el ensamblaje de grandes complejos proteicos que llevan a cabo muchas reacciones estrechamente relacionadas con una función biológica común. Las proteínas también se pueden unir a, o incluso integrarse en, las membranas celulares. La capacidad de los socios de unión para inducir cambios conformacionales en proteínas permite la construcción de redes de señalización enormemente complejas. Como las interacciones entre proteínas son reversibles,
Enzimas
El papel más conocido de las proteínas en la célula es como enzimas, que catalizan reacciones químicas. Las enzimas generalmente son altamente específicas y aceleran solo una o algunas reacciones químicas. Las enzimas llevan a cabo la mayoría de las reacciones implicadas en el metabolismo, así como la manipulación del ADN en procesos como la replicación del ADN, la reparación del ADN y la transcripción. Algunas enzimas actúan sobre otras proteínas para agregar o eliminar grupos químicos en un proceso conocido como modificación postraduccional. Se sabe que unas 4.000 reacciones son catalizadas por enzimas. La aceleración de velocidad conferida por la catálisis enzimática es a menudo enorme, tanto como un aumento de 10 veces en la velocidad sobre la reacción no catalizada en el caso de orotato descarboxilasa (78 millones de años sin la enzima, 18 milisegundos con la enzima).
Las moléculas unidas y actuadas por las enzimas se llaman sustratos. Aunque las enzimas pueden constar de cientos de aminoácidos, por lo general, solo una pequeña fracción de los residuos entran en contacto con el sustrato, y una fracción aún menor -de tres a cuatro residuos en promedio- que están directamente involucrados en la catálisis. La región de la enzima que se une al sustrato y contiene los residuos catalíticos se conoce como el sitio activo.
Las proteínas Dirigent son miembros de una clase de proteínas que dictan la estereoquímica de un compuesto sintetizado por otras enzimas.
Señalización celular y unión al ligando
Muchas proteínas están involucradas en el proceso de señalización celular y transducción de señales. Algunas proteínas, como la insulina, son proteínas extracelulares que transmiten una señal de la célula en la que se sintetizaron a otras células en tejidos distantes. Otros son proteínas de membrana que actúan como receptores cuya función principal es unir una molécula de señalización e inducir una respuesta bioquímica en la célula. Muchos receptores tienen un sitio de unión expuesto en la superficie celular y un dominio efector dentro de la célula, que puede tener actividad enzimática o puede experimentar un cambio conformacional detectado por otras proteínas dentro de la célula.
Los anticuerpos son componentes proteicos de un sistema inmune adaptativo cuya función principal es unir antígenos o sustancias extrañas en el cuerpo y apuntarlos a la destrucción. Los anticuerpos pueden secretarse en el entorno extracelular o anclarse en las membranas de células B especializadas conocidas como células plasmáticas. Mientras que las enzimas están limitadas en su afinidad de unión por sus sustratos por la necesidad de conducir su reacción, los anticuerpos no tienen tales restricciones. La afinidad de unión de un anticuerpo a su objetivo es extraordinariamente alta.
Muchas proteínas de transporte de ligandos se unen a biomoléculas pequeñas particulares y las transportan a otras ubicaciones en el cuerpo de un organismo multicelular. Estas proteínas deben tener una alta afinidad de unión cuando su ligando está presente en altas concentraciones, pero también deben liberar el ligando cuando está presente a bajas concentraciones en los tejidos diana. El ejemplo canónico de una proteína de unión a ligando es la hemoglobina, que transporta oxígeno desde los pulmones a otros órganos y tejidos en todos los vertebrados y tiene homólogos cercanos en cada reino biológico. Las lectinas son proteínas de unión a azúcar que son altamente específicas para sus restos de azúcar. Las lectinas típicamente juegan un papel en los fenómenos de reconocimiento biológico que involucran células y proteínas. Los receptores y las hormonas son proteínas de unión altamente específicas.
Las proteínas transmembrana también pueden servir como proteínas de transporte de ligandos que alteran la permeabilidad de la membrana celular a pequeñas moléculas e iones. La membrana sola tiene un núcleo hidrofóbico a través del cual las moléculas polares o cargadas no se pueden difundir. Las proteínas de membrana contienen canales internos que permiten que tales moléculas entren y salgan de la célula. Muchas proteínas de canales iónicos están especializadas para seleccionar solo un ion en particular; por ejemplo, los canales de potasio y sodio a menudo discriminan solo por uno de los dos iones.
Proteínas estructurales
Las proteínas estructurales confieren rigidez y rigidez a los componentes biológicos de otro modo fluidos. La mayoría de las proteínas estructurales son proteínas fibrosas; por ejemplo, el colágeno y la elastina son componentes críticos del tejido conectivo, como el cartílago, y la queratina se encuentra en estructuras duras o filamentosas, como pelo, uñas, plumas, pezuñas y algunas conchas de animales. Algunas proteínas globulares también pueden desempeñar funciones estructurales, por ejemplo, la actina y la tubulina son globulares y solubles como monómeros, pero se polimerizan para formar fibras largas y rígidas que forman el citoesqueleto, lo que permite que la célula mantenga su forma y tamaño.
Otras proteínas que cumplen funciones estructurales son las proteínas motoras como la miosina, la quinesina y la dineína, que son capaces de generar fuerzas mecánicas. Estas proteínas son cruciales para la movilidad celular de organismos unicelulares y los espermatozoides de muchos organismos multicelulares que se reproducen sexualmente. También generan las fuerzas ejercidas contrayendo los músculos y desempeñan papeles esenciales en el transporte intracelular.
Métodos de estudio
Las actividades y las estructuras de las proteínas se pueden examinar in vitro, in vivo e in silico. Los estudios in vitro de proteínas purificadas en ambientes controlados son útiles para aprender cómo una proteína lleva a cabo su función: por ejemplo, los estudios de cinética enzimática exploran el mecanismo químico de la actividad catalítica de una enzima y su afinidad relativa por varias posibles moléculas de sustrato. Por el contrario, los experimentos in vivo pueden proporcionar información sobre el papel fisiológico de una proteína en el contexto de una célula o incluso de un organismo completo. Los estudios in silico usan métodos computacionales para estudiar proteínas.
Purificación de proteínas
Para realizar in vitro análisis, una proteína debe purificarse lejos de otros componentes celulares. Este proceso generalmente comienza con la lisis celular, en la cual la membrana de una célula se rompe y su contenido interno se libera en una solución conocida como lisado crudo. La mezcla resultante se puede purificar usando ultracentrifugación, que fracciona los diversos componentes celulares en fracciones que contienen proteínas solubles; lípidos y proteínas de la membrana; orgánulos celulares y ácidos nucleicos. La precipitación por un método conocido como salazón puede concentrar las proteínas de este lisado. A continuación, se usan diversos tipos de cromatografía para aislar la proteína o proteínas de interés en base a propiedades tales como el peso molecular, la carga neta y la afinidad de unión. El nivel de purificación puede controlarse usando varios tipos de electroforesis en gel si la proteína deseada ' El peso molecular y el punto isoeléctrico son conocidos, por espectroscopía si la proteína tiene características espectroscópicas distinguibles, o mediante ensayos enzimáticos si la proteína tiene actividad enzimática. Además, las proteínas se pueden aislar de acuerdo con su carga mediante electrofocusado.
Para proteínas naturales, una serie de pasos de purificación puede ser necesaria para obtener proteínas suficientemente puras para aplicaciones de laboratorio. Para simplificar este proceso, la ingeniería genética a menudo se usa para agregar características químicas a las proteínas que las hacen más fáciles de purificar sin afectar su estructura o actividad. Aquí, una "etiqueta" que consiste en una secuencia de aminoácidos específica, a menudo una serie de residuos de histidina (una "etiqueta His"), está unida a un extremo de la proteína. Como resultado, cuando el lisado se pasa sobre una columna de cromatografía que contiene níquel, los residuos de histidina ligan el níquel y se unen a la columna mientras que los componentes no etiquetados del lisado pasan sin impedimento. Se han desarrollado varias etiquetas diferentes para ayudar a los investigadores a purificar proteínas específicas de mezclas complejas.
Localización celular
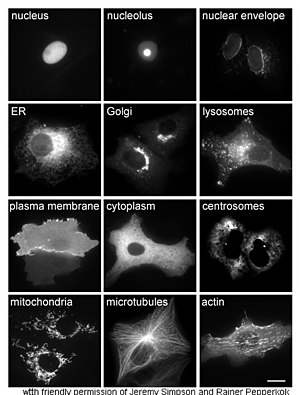
El estudio de las proteínas in vivo a menudo se refiere a la síntesis y localización de la proteína dentro de la célula. Aunque muchas proteínas intracelulares se sintetizan en el citoplasma y proteínas unidas a la membrana o secretadas en el retículo endoplasmático, a menudo no están claros los detalles de cómo las proteínas se dirigen a organelas o estructuras celulares específicas. Una técnica útil para evaluar la localización celular utiliza la ingeniería genética para expresar en una célula una proteína de fusión o quimera que consiste en la proteína natural de interés vinculada a un "informador" tal como la proteína verde fluorescente (GFP). La posición de la proteína fusionada dentro de la célula se puede visualizar de forma limpia y eficiente mediante microscopía, como se muestra en la figura de al lado.
Otros métodos para elucidar la ubicación celular de proteínas requieren el uso de marcadores compartimentales conocidos para regiones tales como ER, Golgi, lisosomas o vacuolas, mitocondrias, cloroplastos, membrana plasmática, etc. con el uso de versiones marcadas con fluorescencia de estos marcadores o de anticuerpos a marcadores conocidos, se vuelve mucho más simple identificar la localización de una proteína de interés. Por ejemplo, la inmunofluorescencia indirecta permitirá la colocalización de fluorescencia y la demostración de la ubicación. Los colorantes fluorescentes se utilizan para marcar los compartimentos celulares con un propósito similar.
También existen otras posibilidades. Por ejemplo, la inmunohistoquímica normalmente utiliza un anticuerpo para una o más proteínas de interés que se conjugan con enzimas que producen señales luminiscentes o cromogénicas que se pueden comparar entre muestras, lo que permite la información de localización. Otra técnica aplicable es la cofracción en gradientes de sacarosa (u otro material) usando centrifugación isopícnica. Si bien esta técnica no prueba la colocalización de un compartimento de densidad conocida y la proteína de interés, aumenta la probabilidad y es más susceptible a estudios a gran escala.
Finalmente, el método estándar de localización celular es la microscopía inmunoelectrónica. Esta técnica también usa un anticuerpo para la proteína de interés, junto con técnicas clásicas de microscopía electrónica. La muestra se prepara para el examen microscópico de electrones normal, y luego se trata con un anticuerpo contra la proteína de interés que se conjuga con un material extremadamente electrodensa, generalmente oro. Esto permite la localización tanto de detalles ultraestructurales como de la proteína de interés.
Mediante otra aplicación de ingeniería genética conocida como mutagénesis dirigida al sitio, los investigadores pueden alterar la secuencia de la proteína y, por lo tanto, su estructura, localización celular y susceptibilidad a la regulación. Esta técnica incluso permite la incorporación de aminoácidos no naturales en proteínas, utilizando tRNA modificados, y puede permitir el diseño racional de nuevas proteínas con propiedades novedosas.
Proteómica
El complemento total de proteínas presentes en un momento en un tipo de célula o célula se conoce como su proteoma, y el estudio de tales conjuntos de datos a gran escala define el campo de la proteómica, nombrada por analogía al campo relacionado de la genómica. Las técnicas experimentales clave en proteómica incluyen electroforesis 2D, que permite la separación de un gran número de proteínas, espectrometría de masas, que permite la identificación rápida de proteínas de alto rendimiento y la secuenciación de péptidos (más a menudo después de la digestión en gel), micromatrices proteicas, que permiten la detección de los niveles relativos de una gran cantidad de proteínas presentes en una célula, y el cribado de dos híbridos, que permite la exploración sistemática de las interacciones proteína-proteína. El complemento total de tales interacciones biológicamente posibles se conoce como el interactoma.
Bioinformática
Se ha desarrollado una amplia gama de métodos computacionales para analizar la estructura, la función y la evolución de las proteínas.
El desarrollo de tales herramientas ha sido impulsado por la gran cantidad de datos genómicos y proteómicos disponibles para una variedad de organismos, incluido el genoma humano. Es simplemente imposible estudiar todas las proteínas de forma experimental, por lo tanto, solo unas pocas se someten a experimentos de laboratorio, mientras que las herramientas computacionales se utilizan para extrapolar a proteínas similares. Tales proteínas homólogas pueden identificarse de manera eficiente en organismos distantemente relacionados mediante alineamiento de secuencias. Se pueden buscar secuencias genómicas y genéticas mediante una variedad de herramientas para ciertas propiedades. Las herramientas de generación de perfiles de secuencia pueden encontrar sitios de enzimas de restricción, marcos de lectura abiertos en secuencias de nucleótidos y predecir estructuras secundarias. Se pueden construir árboles filogenéticos y desarrollar hipótesis evolutivas utilizando un software especial como ClustalW con respecto a la ascendencia de los organismos modernos y los genes que expresan. El campo de la bioinformática es ahora indispensable para el análisis de genes y proteínas.
Determinación de la estructura
Descubrir la estructura terciaria de una proteína, o la estructura cuaternaria de sus complejos, puede proporcionar pistas importantes sobre cómo la proteína realiza su función. Los métodos experimentales comunes para la determinación de la estructura incluyen la cristalografía de rayos X y la espectroscopía de RMN, que pueden producir información a una resolución atómica. Sin embargo, los experimentos de RMN pueden proporcionar información a partir de la cual se puede estimar un subconjunto de distancias entre pares de átomos, y las conformaciones finales posibles para una proteína se determinan resolviendo un problema de geometría de distancia. La interferometría de polarización dual es un método analítico cuantitativo para medir la conformación proteica general y los cambios conformacionales debidos a interacciones u otros estímulos. El dicroísmo circular es otra técnica de laboratorio para determinar la composición interna de las láminas β / α-helicoidales de las proteínas. La microscopía crioelectrónica se usa para producir información estructural de baja resolución sobre complejos proteicos muy grandes, incluidos los virus ensamblados; una variante conocida como cristalografía electrónica también puede producir información de alta resolución en algunos casos, especialmente para cristales bidimensionales de proteínas de membrana. Las estructuras resueltas generalmente se depositan en el Protein Data Bank (PDB), un recurso de libre acceso del que se pueden obtener datos estructurales sobre miles de proteínas en forma de coordenadas cartesianas para cada átomo de la proteína. una variante conocida como cristalografía electrónica también puede producir información de alta resolución en algunos casos, especialmente para cristales bidimensionales de proteínas de membrana. Las estructuras resueltas generalmente se depositan en el Protein Data Bank (PDB), un recurso de libre acceso del que se pueden obtener datos estructurales sobre miles de proteínas en forma de coordenadas cartesianas para cada átomo de la proteína. una variante conocida como cristalografía electrónica también puede producir información de alta resolución en algunos casos, especialmente para cristales bidimensionales de proteínas de membrana. Las estructuras resueltas generalmente se depositan en el Protein Data Bank (PDB), un recurso de libre acceso del que se pueden obtener datos estructurales sobre miles de proteínas en forma de coordenadas cartesianas para cada átomo de la proteína.
Se conocen muchas más secuencias de genes que las estructuras de proteínas. Además, el conjunto de estructuras resueltas está sesgado hacia las proteínas que pueden someterse fácilmente a las condiciones requeridas en la cristalografía de rayos X, uno de los principales métodos de determinación de la estructura. En particular, las proteínas globulares son comparativamente fáciles de cristalizar en preparación para la cristalografía de rayos X. Las proteínas de membrana, por el contrario, son difíciles de cristalizar y están subrepresentadas en el AP. Las iniciativas de genómica estructural han intentado remediar estas deficiencias resolviendo sistemáticamente las estructuras representativas de las principales clases de pliegues. Los métodos de predicción de la estructura proteica intentan proporcionar un medio para generar una estructura plausible para las proteínas cuyas estructuras no se han determinado experimentalmente.
Predicción de estructura y simulación

Complementario al campo de la genómica estructural, predicción de estructura proteica desarrolla modelos matemáticos eficientes de proteínas para predecir computacionalmente las formaciones moleculares en teoría, en lugar de detectar estructuras con observación en el laboratorio. El tipo más exitoso de predicción de estructura, conocido como modelado de homología, se basa en la existencia de una estructura "plantilla" con similitud de secuencia con la proteína que se modela; El objetivo de la genómica estructural es proporcionar una representación suficiente en las estructuras resueltas para modelar la mayoría de las que permanecen. Aunque producir modelos precisos sigue siendo un desafío cuando solo están disponibles estructuras de plantilla lejanamente relacionadas, se ha sugerido que la alineación de secuencias es el cuello de botella en este proceso, ya que se pueden producir modelos bastante precisos si se conoce una alineación de secuencia "perfecta". Muchos métodos de predicción de estructuras han servido para informar el campo emergente de la ingeniería de proteínas, en el que ya se han diseñado nuevos pliegues de proteínas. Un problema computacional más complejo es la predicción de interacciones intermoleculares, como en el acoplamiento molecular y la predicción de interacción proteína-proteína.
Los modelos matemáticos para simular procesos dinámicos de plegamiento y unión de proteínas implican la mecánica molecular, en particular, la dinámica molecular. Las técnicas de Monte Carlo facilitan los cálculos, que explotan los avances en informática paralela y distribuida (por ejemplo, el proyecto Folding @ home que realiza modelos moleculares en GPU). Las simulaciones in silicodescubrieron el plegamiento de pequeños dominios proteínicos α-helicoidales tales como el casco villin y la proteína accesoria del VIH. Los métodos híbridos que combinan la dinámica molecular estándar con la matemática mecánica cuántica exploraron los estados electrónicos de las rodopsinas.
Desorden de proteínas y predicción de la estructura
Muchas proteínas (en Eucaryota ~ 33%) contienen grandes segmentos no estructurados pero biológicamente funcionales y pueden clasificarse como proteínas intrínsecamente desordenadas. La predicción y el análisis del trastorno de proteínas es, por lo tanto, una parte importante de la caracterización de la estructura de proteínas.
Nutrición
La mayoría de los microorganismos y plantas pueden biosintetizar los 20 aminoácidos estándar, mientras que los animales (incluidos los humanos) deben obtener algunos de los aminoácidos de la dieta. Los aminoácidos que un organismo no puede sintetizar por sí solo se denominan aminoácidos esenciales. Las enzimas clave que sintetizan ciertos aminoácidos no están presentes en los animales, como la aspartoquinasa, que cataliza el primer paso en la síntesis de lisina, metionina y treonina del aspartato. Si los aminoácidos están presentes en el medio ambiente, los microorganismos pueden conservar energía absorbiendo los aminoácidos de su entorno y regulando negativamente sus rutas biosintéticas.
En los animales, los aminoácidos se obtienen mediante el consumo de alimentos que contienen proteínas. Las proteínas ingeridas se descomponen en aminoácidos a través de la digestión, que típicamente implica la desnaturalización de la proteína a través de la exposición al ácido y la hidrólisis por enzimas llamadas proteasas. Algunos aminoácidos ingeridos se usan para la biosíntesis de proteínas, mientras que otros se convierten en glucosa a través de la gluconeogénesis o se incorporan al ciclo del ácido cítrico. Este uso de proteínas como combustible es particularmente importante bajo condiciones de inanición ya que permite que las propias proteínas del cuerpo se usen para sustentar la vida, particularmente las que se encuentran en el músculo.
En animales como perros y gatos, las proteínas mantienen la salud y la calidad de la piel al promover el crecimiento y la queratinización del folículo piloso y, por lo tanto, reducen la probabilidad de que los problemas de la piel produzcan malos olores. Las proteínas de mala calidad también tienen un papel en la salud gastrointestinal, aumentando el potencial de flatulencia y compuestos olorosos en los perros porque cuando las proteínas alcanzan el colon en un estado no digerido, se fermentan produciendo sulfuro de hidrógeno, gas, indol y escatol. Los perros y los gatos digieren las proteínas animales mejor que las plantas, pero los productos de origen animal de baja calidad no se digieren bien, incluida la piel, las plumas y el tejido conectivo.
Historia y etimología
Las proteínas fueron reconocidas como una clase distinta de moléculas biológicas en el siglo XVIII por Antoine Fourcroy y otros, que se distinguen por la capacidad de las moléculas para coagular o flocular en los tratamientos con calor o ácido. Los ejemplos notados en ese momento incluían la albúmina de claras de huevo, albúmina de suero sanguíneo, fibrina y gluten de trigo.
Las proteínas fueron descritas por primera vez por el químico holandés Gerardus Johannes Mulder y nombradas por el químico sueco Jöns Jacob Berzelius en 1838. Mulder llevó a cabo análisis elementales de proteínas comunes y descubrió que casi todas las proteínas tenían la misma fórmula empírica, C 400 H 620 N 100 O 120 P 1 S 1 . Llegó a la conclusión errónea de que podrían estar compuestos por un solo tipo de molécula (muy grande). El término "proteína" para describir estas moléculas fue propuesto por el asociado de Mulder Berzelius; la proteína se deriva de la palabra griega πρώτειος ( proteios ), que significa "primaria", "a la cabeza" o "de pie al frente", + -in. Mulder pasó a identificar los productos de la degradación de proteínas como el aminoácido leucina para el cual encontró un peso molecular (casi correcto) de 131 Da. Antes de "proteína", se usaban otros nombres, como "albúminas" o "materiales albuminosos" ( Eiweisskörper , en alemán).
Los primeros científicos nutricionales como el alemán Carl von Voit creían que la proteína era el nutriente más importante para mantener la estructura del cuerpo, porque en general se creía que "la carne se hace carne". Karl Heinrich Ritthausen extendió formas conocidas de proteínas con la identificación del ácido glutámico. En la Estación Experimental Agrícola de Connecticut, Thomas Burr Osborne compiló una revisión detallada de las proteínas vegetales. Trabajando con Lafayette Mendel y aplicando la ley de Liebig del mínimo en ratas de laboratorio de alimentación, se establecieron los aminoácidos nutricionalmente esenciales. El trabajo fue continuado y comunicado por William Cumming Rose. La comprensión de las proteínas como polipéptidos vino a través del trabajo de Franz Hofmeister y Hermann Emil Fischer en 1902.
La dificultad para purificar las proteínas en grandes cantidades hizo que fuera muy difícil para los primeros bioquímicos proteínicos estudiar. Por lo tanto, los primeros estudios se centraron en proteínas que podrían purificarse en grandes cantidades, por ejemplo, las de sangre, clara de huevo, diversas toxinas y enzimas digestivas / metabólicas obtenidas de mataderos. En la década de 1950, Armor Hot Dog Co. purificó 1 kg de ribonucleasa A pancreática bovina pura y la puso a disposición de los científicos; este gesto ayudó a la ribonucleasa A a convertirse en un objetivo principal para el estudio bioquímico durante las siguientes décadas.

A Linus Pauling se le atribuye la exitosa predicción de estructuras secundarias proteicas regulares basadas en enlaces de hidrógeno, una idea presentada por primera vez por William Astbury en 1933. El trabajo posterior de Walter Kauzmann sobre desnaturalización, basado en parte en estudios previos de Kaj Linderstrøm-Lang, contribuyó comprensión del plegamiento de proteínas y estructura mediada por interacciones hidrofóbicas.
La primera proteína en ser secuenciada fue la insulina, de Frederick Sanger, en 1949. Sanger determinó correctamente la secuencia de aminoácidos de la insulina, demostrando de manera concluyente que las proteínas consistían en polímeros lineales de aminoácidos en lugar de cadenas ramificadas, coloides o ciclones. Ganó el Premio Nobel por este logro en 1958.
Las primeras estructuras de proteínas que se resolvieron fueron la hemoglobina y la mioglobina, por Max Perutz y Sir John Cowdery Kendrew, respectivamente, en 1958. A partir de 2017, Protein Data Bank tiene más de 126,060 estructuras de proteínas de resolución atómica. En tiempos más recientes, la microscopía crioelectrónica de grandes conjuntos macromoleculares y la predicción computacional de la estructura proteica de dominios de proteínas pequeñas son dos métodos que se acercan a la resolución atómica.
Obtenido de: https://en.wikipedia.org/wiki/Protein