Escritura latina
Definición
| Latín romano | |
|---|---|
 | |
| Tipo | Alfabeto impuro bicameral |
| Idiomas |
|
Periodo de tiempo | ~ 700 a. C.-presente |
Sistemas hermanas | Cirílico armenio georgiano copto rúnico / futhark |
| Dirección | De izquierda a derecha |
| ISO 15924 | Latn, 215 |
Alias Unicode | latín |
Rango Unicode | Ver caracteres latinos en Unicode |
Existen varios alfabetos de escritura latina, que difieren en grafemas, colación y valores fonéticos del alfabeto latino clásico.
El alfabeto latino es la base del alfabeto fonético internacional, y las 26 letras más extendidas son las letras que figuran en el alfabeto latino básico de ISO.
La escritura latina es la base de la mayor cantidad de alfabetos de cualquier sistema de escritura y es el sistema de escritura más adoptado en el mundo (comúnmente utilizado por alrededor del 70% de la población mundial). La escritura latina se utiliza como el método estándar de escritura en la mayoría de los idiomas de Europa occidental y central, así como en muchos idiomas en otras partes del mundo.
Nombre
El guión se llama romaní o latín, en referencia a su origen en la antigua Roma. En el contexto de la transliteración, a menudo se encuentra el término "romanización" o "romanización". Unicode usa el término "latino" como lo hace la Organización Internacional de Normalización (ISO).
El sistema numérico se llama sistema de números romanos; y la colección de los elementos, números romanos. Los números 1, 2, 3 ... son números de guión latino / romano para el sistema numérico hindú-árabe.
Historia
Antiguo alfabeto itálico
| Letras | 𐌀 | 𐌁 | 𐌂 | 𐌃 | 𐌄 | 𐌅 | 𐌆 | 𐌇 | 𐌈 | 𐌉 | 𐌊 | 𐌋 | 𐌌 | 𐌍 | 𐌎 | 𐌏 | 𐌐 | 𐌑 | 𐌒 | 𐌓 | 𐌔 | 𐌕 | 𐌖 | 𐌗 | 𐌘 | 𐌙 | 𐌚 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Transcripción | UN | segundo | do | re | mi | V | Z | H | Θ | yo | K | L | METRO | norte | Ξ | O | PAG | Ś | Q | R | S | T | Y | X | Φ | Ψ | F |
Alfabeto latino arcaico
| Como viejo cursiva | 𐌀 | 𐌁 | 𐌂 | 𐌃 | 𐌄 | 𐌅 | 𐌆 | 𐌇 | 𐌉 | 𐌊 | 𐌋 | 𐌌 | 𐌍 | 𐌏 | 𐌐 | 𐌒 | 𐌓 | 𐌔 | 𐌕 | 𐌖 | 𐌗 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Como latino | UN | segundo | do | re | mi | F | Z | H | yo | K | L | METRO | norte | O | PAG | Q | R | S | T | V | X |
La letra ⟨C⟩ era la forma occidental de la gamma griega, pero se usó para los sonidos / ɡ / y / k / similares, posiblemente bajo la influencia de etrusco, que podría haber carecido de cualquier voz plosiva. Más tarde, probablemente durante el siglo III aC, la letra ⟨Z⟩ - innecesaria para escribir latín correctamente - fue reemplazada por la nueva letra ⟨G⟩, una ⟨C⟩ modificada con un pequeño trazo vertical, que tomó su lugar en el alfabeto. A partir de entonces, ⟨G⟩ representó la voz sonora / ɡ / , mientras que ⟨C⟩ se reservó generalmente para la voz sin voz / k / . La letra ⟨K⟩ se usó solo en raras ocasiones, en un pequeño número de palabras como Kalendae , a menudo de manera intercambiable con ⟨C⟩.
Alfabeto latino clásico
Después de la conquista romana de Grecia en el siglo I a. C., el latín adoptó las letras griegas ⟨Y⟩ y ⟨Z⟩ (o readoptadas, en este último caso) para escribir préstamos griegos, colocándolos al final del alfabeto. Un intento del emperador Claudio de presentar tres cartas adicionales no duró. Así fue durante el período latino clásico que el alfabeto latino contenía 23 letras:
| Carta | UN | segundo | do | re | mi | F | GRAMO | H | yo | K | L | METRO | norte | O | PAG | Q | R | S | T | V | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Nombre latino (majus) | un | ser | cé | Delaware | mi | ef | gé | decir ah | ꟾ | ká | el | em | es | ó | Educación física | q v | er | es | té | v | ix | ꟾ graeca | zéta |
| Nombre latino | un | ser | cē | Delaware | mi | ef | gē | decir ah | yo | kā | el | em | es | ō | Educación física | qū | er | es | tē | ū | ix | ī Graeca | zēta |
| Pronunciación de latín (IPA) | un | ser | keː | Delaware | mi | ɛf | ɡeː | decir ah | yo | kaː | ɛl | ɛm | ɛn | oː | Educación física | kuː | ɛr | ɛs | teː | uː | iks | iː ɪraɪka | Dzeːta |
Alfabeto latino básico de ISO
| Alfabeto latino mayúscula | UN | segundo | do | re | mi | F | GRAMO | H | yo | J | K | L | METRO | norte | O | PAG | Q | R | S | T | U | V | W | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Alfabeto latino minúsculo | un | segundo | do | re | mi | F | gramo | h | yo | j | k | l | metro | norte | o | pag | q | r | s | t | tu | v | w | X | y | z |
El uso de las letras I y V para las consonantes y las vocales resultó inconveniente ya que el alfabeto latino se adaptó a las lenguas germánicas y romances. W se originó como un V duplicado (VV) utilizado para representar el sonido [w] encontrado en el inglés antiguo ya en el siglo VII. Llegó a ser de uso común a fines del siglo XI, reemplazando la letra rúnica de Wynn que se había utilizado para el mismo sonido. En las lenguas romances, la forma minúscula de V era una u redondeada ; de esto se derivó una U mayúscula redondeada para la vocal en el siglo XVI, mientras que un vminúsculo nuevo y puntiagudo se derivó de V para la consonante. En el caso de I, una forma swash de palabra final, j, llegó a ser usado para la consonante, con la forma no expandida restringida al uso vocal. Tales convenciones fueron erráticas durante siglos. J se introdujo en inglés para la consonante en el siglo XVII (había sido raro como vocal), pero no se consideró universalmente una letra distinta en el orden alfabético hasta el siglo XIX.
En la década de 1960, se hizo evidente para las industrias de computadoras y telecomunicaciones en el Primer Mundo que se necesitaba un método no propietario de codificación de caracteres. La Organización Internacional de Normalización (ISO) encapsuló el alfabeto latino en su estándar (ISO / IEC 646). Para lograr una aceptación generalizada, esta encapsulación se basó en el uso popular. Como los Estados Unidos ocuparon un lugar preeminente en ambas industrias durante la década de 1960, el estándar se basó en el Código Estándar Estadounidense para el Intercambio de Información ya publicado ., mejor conocido como ASCII, que incluía en el juego de caracteres las letras 26 × 2 (mayúsculas y minúsculas) del alfabeto inglés. Las normas posteriores emitidas por la ISO, por ejemplo ISO / IEC 10646 (Unicode Latin), han seguido definiendo las letras 26 × 2 del alfabeto inglés como el alfabeto latino básico con extensiones para manejar otras letras en otros idiomas.
Untado
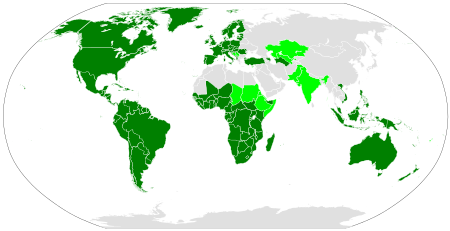
El alfabeto latino se extendió, junto con el latín, desde la península italiana a las tierras que rodean el mar Mediterráneo con la expansión del Imperio Romano. La mitad oriental del Imperio, incluidos Grecia, Turquía, Levante y Egipto, siguió utilizando el griego como lingua franca, pero el latín se hablaba ampliamente en la mitad occidental, y como las lenguas romances occidentales evolucionaron a partir del latín, continuaron usar y adaptar el alfabeto latino.
Edades medias
Con la difusión del cristianismo occidental durante la Edad Media, el alfabeto latino fue adoptado gradualmente por los pueblos del norte de Europa que hablaban las lenguas celtas (desplazando el alfabeto Ogham) o germánicas (desplazando alfabetos rúnicos anteriores) o las lenguas bálticas, así como por los hablantes de varias lenguas de Uralic, especialmente húngaro, finlandés y estonio.
La escritura latina también se usó para escribir las lenguas eslavas occidentales y varias lenguas eslavas del sur, ya que las personas que las hablaron adoptaron el catolicismo romano. Los hablantes de lenguas eslavas orientales generalmente adoptaron el cirílico junto con el cristianismo ortodoxo. El idioma serbio usa ambos scripts, con cirílico que predomina en la comunicación oficial y el latín en otros lugares, según lo determina la Ley de Uso Oficial del Idioma y el Alfabeto.
Desde el siglo XVI
Hasta 1500, el guión latino se limitaba principalmente a los idiomas hablados en Europa occidental, septentrional y central. Los eslavos cristianos ortodoxos de Europa oriental y sudoriental usaban sobre todo cirílico, y el alfabeto griego era utilizado por los hablantes de griego en el este del Mediterráneo. La escritura árabe estaba muy extendida dentro del Islam, tanto entre los árabes como entre las naciones no árabes como los iraníes, indonesios, malayos y turcos. La mayoría del resto de Asia utilizó una variedad de alfabetos Brahmic o el guión chino.
A través de la colonización europea, el alfabeto latino se ha extendido a las Américas, Oceanía, partes de Asia, África y el Pacífico, en formas basadas en los alfabetos español, portugués, inglés, francés, alemán y holandés.
Se utiliza para muchos idiomas austronesios, incluidos los idiomas de Filipinas y Malasia e Indonesia, en sustitución de los alfabetos brahmánicos árabes e indígenas anteriores. Las letras latinas sirvieron como base para las formas del silabario cherokee desarrollado por Sequoyah; sin embargo, los valores de sonido son completamente diferentes.
Desde el siglo XIX
A finales del siglo XIX, los rumanos volvieron al alfabeto latino, que habían utilizado hasta el concilio de Florencia en 1439, principalmente porque el rumano es una lengua romance. Los rumanos eran predominantemente cristianos ortodoxos, y su Iglesia, cada vez más influenciada por Rusia después de la caída de la Constantinopla griega bizantina en 1453 y la captura del patriarca ortodoxo griego, había comenzado a promover el cirílico eslavo.
Bajo el dominio francés y la influencia misionera portuguesa, se ideó un alfabeto latino para el idioma vietnamita, que anteriormente había usado caracteres chinos.
Desde el siglo XX
En 1928, como parte de las reformas de Mustafa Kemal Atatürk, la nueva República de Turquía adoptó un alfabeto latino para el idioma turco, reemplazando un alfabeto árabe modificado. La mayoría de los pueblos de habla turca de la antigua URSS, incluidos los tártaros, los bashkires, los azeríes, los kazajos, los kirguisos y otros, utilizaron el alfabeto de Turkic uniforme con base latina en la década de 1930; pero, en la década de 1940, todos fueron reemplazados por cirílico. Después del colapso de la Unión Soviética en 1991, tres de las repúblicas de habla turca recién independizadas, Azerbaiyán, Uzbekistán y Turkmenistán, así como la Moldavia de habla rumana, adoptaron oficialmente los alfabetos latinos para sus idiomas.
Kazajstán, Kirguistán, Tayikistán de habla iraní y la región separatista de Transnistria conservaron el alfabeto cirílico, principalmente debido a sus estrechos vínculos con Rusia. En los años 1930 y 1940, la mayoría de los kurdos reemplazó el alfabeto árabe con dos alfabetos latinos. Aunque el único gobierno oficial kurdo utiliza un alfabeto árabe para documentos públicos, el alfabeto latino kurdo sigue siendo ampliamente utilizado en toda la región por la mayoría de los hablantes de kurdo.
En 2015, el gobierno kazajo anunció que el alfabeto latino reemplazaría el cirílico como el sistema de escritura para el idioma kazajo para 2025.
Estándares internacionales
En la década de 1960, se hizo evidente para las industrias de computadoras y telecomunicaciones en el Primer Mundo que se necesitaba un método no propietario de codificación de caracteres. La Organización Internacional de Normalización (ISO) encapsuló el alfabeto latino en su estándar (ISO / IEC 646). Para lograr una aceptación generalizada, esta encapsulación se basó en el uso popular.
Como Estados Unidos ocupó un puesto preeminente en ambas industrias durante la década de 1960, el estándar se basó en el American Standard Code for Information Interchange ya publicado , más conocido como ASCII, que incluía en el juego de caracteres 26 × 2 (mayúsculas y minúsculas) letras del alfabeto inglés. Las normas posteriores emitidas por la ISO, por ejemplo ISO / IEC 10646 (Unicode Latin), han seguido definiendo las letras 26 × 2 del alfabeto inglés como el alfabeto latino básico con extensiones para manejar otras letras en otros idiomas.
Según lo utilizado por varios idiomas
En el transcurso de su uso, el alfabeto latino fue adaptado para su uso en nuevos idiomas, a veces representando fonemas que no se encuentran en los idiomas que ya se escribieron con los caracteres romanos. Para representar estos nuevos sonidos, se crearon extensiones, ya sea mediante la adición de signos diacríticos a letras existentes, uniendo varias letras para hacer ligaduras, creando formas completamente nuevas o asignando una función especial a pares o trillizos de letras. A estas nuevas formas se les asigna un lugar en el alfabeto al definir un orden alfabético o secuencia de intercalación, que puede variar según el idioma en particular.
Letras
Algunos ejemplos de nuevas letras al alfabeto latino estándar son las letras rúnicas wynn ⟨Ƿ / ƿ⟩ y thorn ⟨Þ / þ⟩, y la letra eth ⟨Ð / ð⟩, que se agregaron al alfabeto del inglés antiguo. Otra letra irlandesa, la g insular , se convirtió en yogh ⟨Ȝ / ȝ⟩, utilizada en inglés medio. Wynn fue reemplazado más tarde con la nueva letra ⟨w⟩, eth y thorn con ⟨th⟩, y yogh con ⟨gh⟩. Aunque los cuatro ya no forman parte de los alfabetos inglés o irlandés, eth y thorn todavía se usan en los modernos alfabetos islandeses y feroeses.
Algunos idiomas de África occidental, central y meridional utilizan algunas letras adicionales que tienen un valor de sonido similar a sus equivalentes en el IPA. Por ejemplo, Adangme usa las letras ⟨Ɛ / ɛ⟩ y ⟨Ɔ / ɔ⟩, y Ga usa ⟨Ɛ / ɛ⟩, ⟨Ŋ / ŋ⟩ y ⟨Ɔ. Hausa usa ⟨Ɓ / ɓ⟩ y ⟨Ɗ / ɗ⟩ para implosivos, y ⟨Ƙ / ƙ⟩ para un expulsivo. Los africanistas los han estandarizado en el alfabeto de referencia africano.
El idioma de Azerbaiyán también tiene la letra escrita como "Ə", que representa la vocal no redondeada del frente casi abierto.
Multigrafos
Un dígrafo es un par de letras usadas para escribir un sonido o una combinación de sonidos que no se corresponde con las letras escritas en secuencia. Los ejemplos son ⟨ch⟩, ⟨ng⟩, ⟨rh⟩, ⟨sh⟩ en inglés, y ⟨ij⟩ en holandés. En holandés, el ⟨ij⟩ se escribe en mayúscula como ⟨IJ⟩ o la ligadura ⟨IJ⟩, pero nunca como ⟨Ij⟩, y con frecuencia toma la apariencia de una ligadura ⟨ij⟩ muy similar a la letra ⟨ÿ⟩ en la escritura a mano.
Un trigraph se compone de tres letras, como el alemán ⟨sch⟩, el bretón ⟨c'h⟩ o el milanés ⟨oeu⟩. En las ortografías de algunos idiomas, los dígrafos y los trigrafos se consideran letras independientes del alfabeto por derecho propio. La capitalización de dígrafos y trigrafos depende del idioma, ya que sólo la primera letra puede ser capitalizada, o todas las letras de componentes simultáneamente (incluso para las palabras escritas en TitleCase, donde las letras después el dígrafo o trigraph se dejan en minúscula).
Ligaduras
Una ligadura es una fusión de dos o más letras ordinarias en un nuevo glifo o personaje. Ejemplos son ⟨Æ / æ⟩ (de ⟨AE⟩, llamado "ceniza"), ⟨Œ / œ⟩ (de ⟨OE⟩, a veces llamado "oethel"), la abreviatura ⟨&⟩ (de Latin et "y") , y el símbolo alemán ⟨ß⟩ ("S aguda" o "eszet", de ⟨sz⟩ o ⟨ss⟩, la forma medial arcaica de ⟨s⟩, seguida por un ⟨z⟩ o ⟨s⟩).
Diacríticos

Un diacrítico, en algunos casos también llamado acento, es un pequeño símbolo que puede aparecer arriba o debajo de una letra, o en alguna otra posición, como el signo de diéresis usado en los caracteres alemanes ⟨ä⟩, ⟨ö⟩, ⟨ü ⟩ O los caracteres rumanos ă, â, î, ş, ţ. Su función principal es cambiar el valor fonético de la letra a la que se agrega, pero también puede modificar la pronunciación de una sílaba o palabra completa, o distinguir entre homógrafos. Al igual que con las letras, el valor de los signos diacríticos depende del idioma. El inglés y el holandés son los únicos idiomas europeos modernos principales que no requieren diacríticos para las palabras nativas (aunque una diéresis puede usarse en palabras como "cooperación").
Colación
Algunas letras modificadas, como los símbolos ⟨å⟩, ⟨ä⟩ y ⟨ö⟩, se pueden considerar como nuevas letras individuales en sí mismas y se les asigna un lugar específico en el alfabeto para fines de intercalación, separados de la letra de en el que se basan, como se hace en sueco. En otros casos, como con ⟨ä⟩, ⟨ö⟩, ⟨ü⟩ en alemán, esto no se hace; combinaciones de letras diacríticas que se identifican con su letra de base. Lo mismo se aplica a los dígrafos y trigrafos. Diferentes diacríticos pueden tratarse de manera diferente en colación dentro de un único idioma. Por ejemplo, en español, el carácter ⟨ñ⟩ se considera una letra, y se ordena entre ⟨n⟩ y ⟨o⟩ en diccionarios, pero las vocales acentuadas ⟨á⟩, ⟨é⟩, ⟨ó⟩, ⟨ ú⟩ no están separados de las vocales no acentuadas ⟨a⟩, ⟨e⟩, ⟨i⟩, ⟨o⟩, ⟨u⟩.
Capitalización
Los idiomas que usan el guión latino actualmente generalmente usan letras mayúsculas para comenzar párrafos y oraciones y nombres propios. Las reglas para la capitalización han cambiado con el tiempo, y diferentes idiomas han variado en sus reglas de capitalización. El inglés antiguo, por ejemplo, rara vez se escribía con nombres propios escritos con mayúscula; mientras que el inglés moderno del siglo XVIII tenía a menudo todos los sustantivos en mayúscula, del mismo modo que hoy se escribe el alemán moderno, por ejemplo, Alle Schwestern der alten Stadt hatten die Vögel gesehen ("Todas las hermanas de la ciudad antigua habían visto pájaros"). .
Romanización
Las palabras de los idiomas escritos de forma nativa con otros scripts, como el árabe o el chino, generalmente se transcriben o se transcriben cuando se incrustan en el texto del script latino o en la comunicación internacional multilingüe, un proceso denominado romanización.
Si bien la romanización de dichos idiomas se usa principalmente en niveles no oficiales, ha sido especialmente prominente en los mensajes informáticos, donde solo el código ASCII de 7 bits está disponible en sistemas más antiguos. Sin embargo, con la introducción de Unicode, la romanización se está volviendo cada vez menos necesaria. Tenga en cuenta que los teclados utilizados para ingresar ese texto aún pueden restringir a los usuarios el texto romanizado, ya que solo los caracteres ASCII o del alfabeto latino pueden estar disponibles.